

When I was leading the Network Security Group at the US Naval Postgraduate School, I was overwhelmed with the degree of failure we experienced. The amount of events, complexity of investigations and immature security infrastructure created an environment of perpetual failure. After gathering the basic business metrics I discussed in Metering Incident Response 101 I decided it was time to push the problem up the chain of command.
Admitting Failure is Cathartic
It may seem counter-intuitive to give your boss a detailed report on all the ways you are failing to do the job you were hired for but it is liberating and the second step (after collecting metrics) toward building a successful incident response team. The failure report is how you hold each other accountable.
Why Failure Happens
The high level variables of failure are pretty simple. You either need better tools, better process, more people or different policy. In Metering Incident Response 101 we defined two metrics that are impacted by these four variables: number of investigations (n) and time per investigation (t.)
Better Tools
A third metric that we haven’t explored yet is the number of incidents that were not detected (d.) These failures are almost always connected to tools. If you do not have a solution for doing malware sandboxing, it is unlikely you will catch zero-day malware until there is a signature for it. Like-wise if you don’t have a tool looking for data loss, you are always going to fail at detecting insider data theft. Models like SANS Critical Security Controls help define how to cover these gaps with available market tools. Justifying systemic coverage failure should be the first part of the Failure Report. It should provide recommendations on what solutions exist for reducing d to acceptable levels.
In addition to reducing d, tools can also reduce number of investigations (n) by automatically blocking events. If a tool can reduce the number of events generated by stopping the incident early and definitively, it is normally a good investment. When testing a solution, do A-B testing on the impact of n of the solution.
Tools also have the ability to reduce the time per investigation (t) by providing investigators with necessary information more quickly.
When recommending tools to reduce failure, succinct statements like this are most effective, “By implementing [tool] we will enable detection of zero-day malware covering a high-risk gap. Additionally, testing shows it will reduce incidents by 50 per month and provide data that accelerates investigations by 25% saving the organization more than 100 labor hours per month.”
Better Process
When putting a stopwatch to investigators, it’s also prudent to document what steps they take in an investigation. Comparing with other internal responders and consulting with peers at other organizations can help every member of the team. Documented process also has other benefits that I’ll discuss in a future entry. Improved process is generally the easiest to implement and requires the least approval.
Improving Policy
Some situations can be greatly improved by just changing enforcement policies. Changing password complexity policy can have an immediate, positive impact on reducing the number of events to be investigated (n.) Likewise, forcing departments to use centrally managed services reduces cost and risk over owning their own. These changes are normally inexpensive in capital but the most expensive in political energy and require some solid negotiating skills and diplomacy.
More People
Once you have maximized tools, process & policy all you can do is get a bigger team. That may be through hiring or partnering with others. If you have four people and need eight, you will burn out your resources and regularly fail. It will lead to low morale and make it easy to poach your remaining staffers by other organizations.
Adding head count is one of the hardest sales inside an organization. It is permanent operational expense (OPEX) with a heavy on-boarding cost and risk that the new team member brings. Estimated costs to hire an entry level analyst can exceed $60,000 with annual OPEX of $160,000. If they quit or have to be discharged, costs are an additional $25,000 plus repeating the on-boarding costs again. Be sure that the other approaches (tools, policy, process) are exhausted before putting out a requisition for headcount. Also be certain you are hiring the right person and have what it takes to retain them.
Pulling the Failure Report Together
Once you have the metrics and some plans, keep the failure report simple and succinct. You should have initiatives to address failure written up separately from the monthly failure report. The meat of the report looks like this:
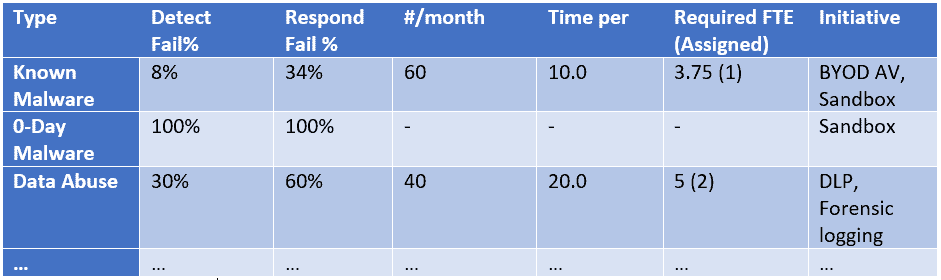
Once you have 3 or more months of these metrics, trend lines can be plotted to show meaningful progress toward success. While writing the first Failure Report may seem like an indictment, subsequent reports with good planning and coordination can show the success you and your team have built in turning from systemic failure to organization success.
The post Failure Reports appeared first on WitFoo.